Hiding error details on production in ZF2
Unlike ZF1, Zend Framework 2 doesn't have a built-in concept of "production" or "development" environments, so by default, the error pages (which include a full stack trace) will appear on your production servers as well as your development environments. This isn't really desirable, but it is easy to change. The local.php config files are excluded from source control, and so are the place for environment-specific configuration.
To hide the error details, edit config/autoload/local.php on your production server and add (to the existing array defined in that file):
'view_manager' => array(
'display_exceptions' => false
)
And that will hide your error details on your production server only.
Fixing Apache after Ubuntu 13.10 upgrade
Ubuntu 13.10 was released yesterday. As well as other package updates, it includes an upgrade from Apache 2.2 to 2.4, which broke a few things on my dev machine.
After the upgrade I was getting the standard "It works!" Apache message on all of my virtual hosts. Running apache2ctl configtest gave me the familiar warning:
Could not reliably determine the server's fully qualified domain name, using 127.0.1.1. Set the 'ServerName' directive globally to suppress this message
You often get this error in an out-of-the-box Ubuntu setup as you need to tell Apache what hostname to use as the default. I'd previously fixed this by creating a config file at /etc/apache2/conf.d/fqdn that contains only:
ServerName localhost
so first I had to investigate why this was no longer working. It turned that Apache 2.4 no longer reads configs from conf.d. If you check the end of apache2.conf, you'll see that it now looks in a folder called conf-enabled instead:
# Include generic snippets of statements IncludeOptional conf-enabled/*.conf
This folder contains symlinked files pointing at conf-available, making the conf setup similar to the approach used for vhosts. So, to fix the error I moved all of my configuration files from conf.d to /etc/apache2/conf-available/, added a .conf file extension to each one, and then ran:
a2enconf fqdn
to setup the symlink.
After restarting Apache, the FQDN error was gone, but I was still getting the "It works!" message for all my vhosts. I had another look at the main Apache config and found:
# Include the virtual host configurations: IncludeOptional sites-enabled/*.conf
So by default Apache expects the vhost files to have a .conf file extension (which it didn't before). Mine just used the hostname as the filename. So I renamed each of these and updated the symlinks that point to them.
After that everything was back to normal.
A full 2.2 to 2.4 upgrade guide is available in case you have any other issues. Of particular note is the change to the syntax for 'Deny from' and 'Require', so if you start getting "403 Forbidden" errors on things that previously worked you'll probably need to update those directives.
Many/all of these issues could be mitigaged by either keeping old configs during the upgrade or by installing the provided compatibility module, but in development I prefer to always install package maintainer's configs when upgrading so that I know how to fix things if they were to go wrong in production.
RIP Google Reader
Google Reader shut its doors today. I am one of the many who'll mourn it's closure, as it's a service I've used on a daily basis for many years.
For me it was the synchronisation that was the killer feature. I mostly used the web-based version, but I also have the Android client installed on my mobile and tablet. It was great to be able to fire up the client when I had a few minutes to kill (e.g. whilst on a train), knowing that I'd find a few interesting articles to read.
I track around 200 or so RSS feeds - mostly blogs, but also a few tech news sites. It served as the backend for Google Listen (Android podcast client), and up until Twitter's recent API change I used it to track a handful of Twitter searches (a very simple way of monitoring Twitter for certain phrases or URLs). I even used it to 'follow' some Twitter accounts, via. a Yahoo Pipes filter, for people who post links in such high volume that they would drown out all the other people I follow if I was to follow them via. my normal Twitter client.
The reason Google gave for its shutdown was a decline in usage, and their attempt to focus on fewer products. I certainly get a lot of my info these days via. Twitter and social bookmarking sites, but RSS is still the primary source for me. And as for focus, to quote a Hacker News comment:
"Yeah, Reader held back the development of the robot car, glasses, floating balloon internet and the brazilian social site..."
Whatever the real reason is, I find it strange that Google didn't try and at least gently steer the Reader refugees towards one of their other products. It wouldn't be a huge stretch to have some sort of 'follow' feature on Google+ that allows you to track an RSS feed (which could later be claimed by an individual or company as part of their profile). G+ already has the link sharing and comment features, and the recently introduced auto-tagging is pretty impressive, and would work nicely for auto-discovery.
As for the Reader alternatives, I tried Feedly for a week or two after Google's announcement in March. It's a nice product, but something about it didn't quite sit right with me. More recently I looked at The Old Reader and Yoleo Reader, which look like decent enough Google Reader clones, but I'm a little wary of signing up to one of the new upstarts. For now I've installed Tiny Tiny RSS. It's open source and self-hosted (so no risk of that disappearing), and fairly similar feature-wise to Google Reader with a couple of nice extras. I figure I'll stick with that for the next six months or so and then take another look at the alternatives and see if any of them have evolved into something special.
But Google Reader, you will be missed.
Some thoughts on Ubuntu's Web Apps feature
Ubuntu 12.10 introduced the "web apps" feature, which promised better integration between the desktop and certain web sites. This feature worked by way of a browser extension, which was only supported by Firefox and Chromium (not Chrome - my browser of choice at the time), and then there were installable add-ons for various popular sites.
Shortly before 13.04 was released I switched from Chrome to Chromium full-time, as I wanted to see what this feature was like to use day-to-day, and then see how it had been evolved in the new Ubuntu release, six months on. After installing 13.04, I was a little disappointed to learn that no changes had been made to this feature at all, as what's there at the moment seems very incomplete.
Looking at some of the extensions individually:
Gmail - The main thing I'd expect from this is new email notification (tied in with notify-osd). For me this worked sporadically (on perhaps 1/4 emails), but it only supports one Google Account (I'm usually logged in to at least two), and there's no way to control which one it uses. No tie-in with the Ubuntu Online Accounts feature.
YouTube - All I really wanted from this one was for it to hook into the OS sound controls, as it would be great to be able to play or pause a YouTube video by hitting the relevant media buttons on my keyboard (like I can with local videos). This one also only worked sporadically, with no obvious pattern as to why.
BBC News - This one I tried but quicky uninstalled. When you load it up it gives you a series of OS notifications for the current top news headlines (almost too quick to read). I can see the thinking behind having a notification when a new 'breaking news' story is posted, but since you need to have BBC News open in your browser anyway for this to work, it doesn't seem that useful.
Reddit - This one has an annoying bug where it incorrectly reads your Reddit 'reputation' score as the number of unread messages. So with this loaded you have a permanent blue 'new notification' icon on your desktop. If you load the app up via. the launcher (giving it its own chrome-less browser window), clicking on self.XXX Reddit links open in new tabs, but external links you click on open in your main browser window, which is a bit confusing.
I also tried the Google Docs and Google Calendar extensions - these didn't appear to do anything. Google Plus I tried - presumably this at least gives you OS notifications for G+ notifications, but for me these are so infrequent that this was tricky to test. Same goes for LinkedIn.
All in all this seems like a missed opportunity. I'm not sure if Canonical made these initial extensions with the hope that the vendors themselves would pick them up and evolve them, or whether these are all just sitting on someone's to-do list somewhere. But as everything moves into "the cloud", there seems to be a lot of potential here to further blur the lines between desktop and online apps, and provide a better experience for the user.
More than any other Ubuntu feature, I hope this gets some love in a future release. In particular, if there's a way to remove the dependency on an open browser tab (with opt-in push notifications for the various services), this could be a really awesome feature.
IE testing on Ubuntu with Microsoft's new Virtual Machine images
For a while, Microsoft provided Internet Explorer Virtual PC images that could be used to install a Virtual Machine specifically for IE testing. However, getting these running in Linux was a bit of a faff, and at times I had issues where even freshly downloaded images required a Windows activation key (making them pointless). Happily, Microsoft now has a site specifically about IE testing which includes cross-platform images to make things easier.
To use these in Ubuntu, first you'll need to install VirtualBox, which you can find in the Ubuntu Software Centre. Next, visit Microsoft's virtualization downloads page, select 'Linux' as the desired testing OS, and then 'VirtualBox' (the only option) from the platform dropdown on the right. This will give you a list of download links, grouped by Internet Explorer versions. The older IE versions, which only run on XP, have only one download link; whereas the more recent ones have several, as their image file has been split into multiple chunks. The multi-file images each have a text file download link first in the list which includes the URLs to all the file pieces. This means them very easy to download with wget:
Using the IE9 Win7 image as an example, first, download the text file itself:
wget https://az412801.vo.msecnd.net/vhd/IEKitV1_Final/VirtualBox/Linux/IE9_Win7/IE9.Win7.For.LinuxVirtualBox_2.txt
Then pass this text file to wget with the -i flag, which tells wget to download each URL it contains in succession:
wget -i IE9.Win7.For.LinuxVirtualBox_2.txt
(this might take some time depending on the speed of your Internet connection)
Once the files have downloaded, you should end up with one .sfx file and some .rar files in the folder. The next step is to make the .sfx file executable:
chmod +x IE9.Win7.For.LinuxVirtualBox.part1.sfx
and then run it:
./IE9.Win7.For.LinuxVirtualBox.part1.sfx
this will merge the files into one .ova file. OVA is a standard for self-contained virtual machine images which VirtualBox supports.
Next, run VirtualBox, and select 'Import Appliance' from its file menu:
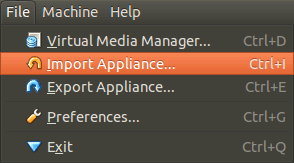
find the .ova file on your hard disk, and when it's opened, click on the highlighted 'Open Appliance' button in the main VirtualBox. This will create the new Virtual Machine which you can then run. That's it - no partitioning required, and you can now test websites using Internet Explorer.
Apparently these images are 90-day limited, although this isn't mentioned on the site. I'm not sure if this is 90 days of use or 90 days from when you first boot up the machine. I also had trouble with some of the images on there, so if you get any cryptic errors give one of the other versions a try.